- salud del servicio
- rendimiento y errores
- análisis de latencia
- cuellos de botella del scheduler y de GPU
Qué necesitas antes
Antes de que este dashboard sea útil, necesitas:- métricas de plataforma activadas en Zylon
- un backend de métricas compatible con Prometheus que ya contenga métricas de Zylon
- una instancia de Grafana con un datasource de Prometheus conectado a ese backend
Importar el dashboard
Descarga grafana-dashboard.json e impórtalo en tu instancia de Grafana mediante Dashboards → Nuevo → Importar. Para el flujo de importación en Grafana, consulta la documentación de importación de dashboards de Grafana.Qué muestra el dashboard
El dashboard está construido a partir de las métricas expuestas en el endpoint/metrics de Triton:
- métricas de Triton Inference Server como recuento de peticiones, latencia, profundidad de cola y salud de GPU
- métricas de vLLM como estado del scheduler, uso de la caché KV, rendimiento de tokens e histogramas de latencia
Filtros del dashboard
Cómo leer el dashboard
Sigue este orden cuando investigues un problema:Paneles por sección
Overview
Indicadores rápidos de salud para tasa de éxito, peticiones por segundo, peticiones concurrentes y profundidad de cola.
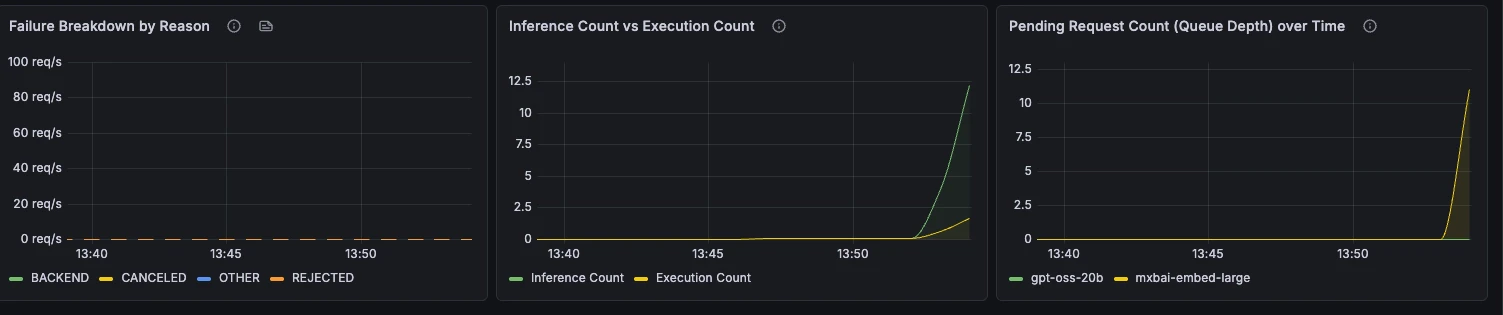
Throughput & Errors
Tasa de peticiones, tasa de fallos, motivos de fallo, comportamiento de batching y profundidad de cola a lo largo del tiempo.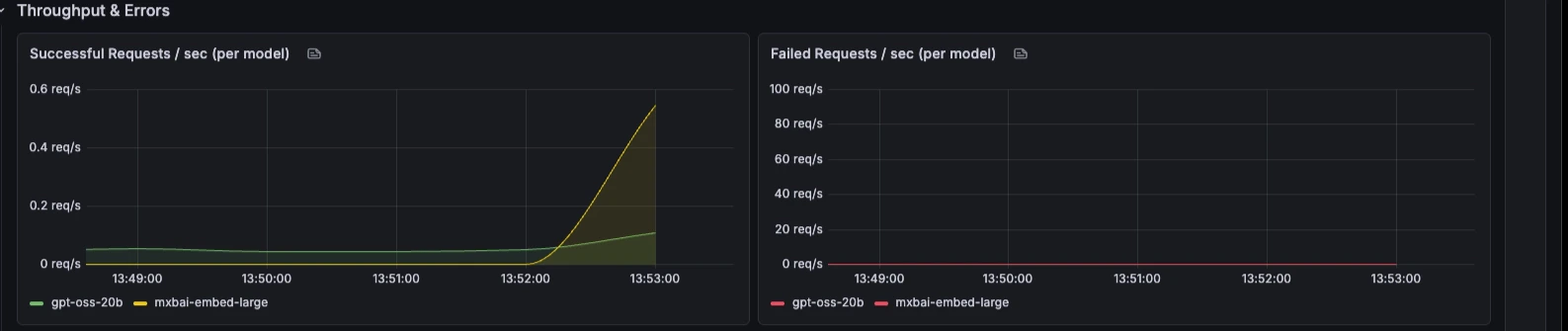
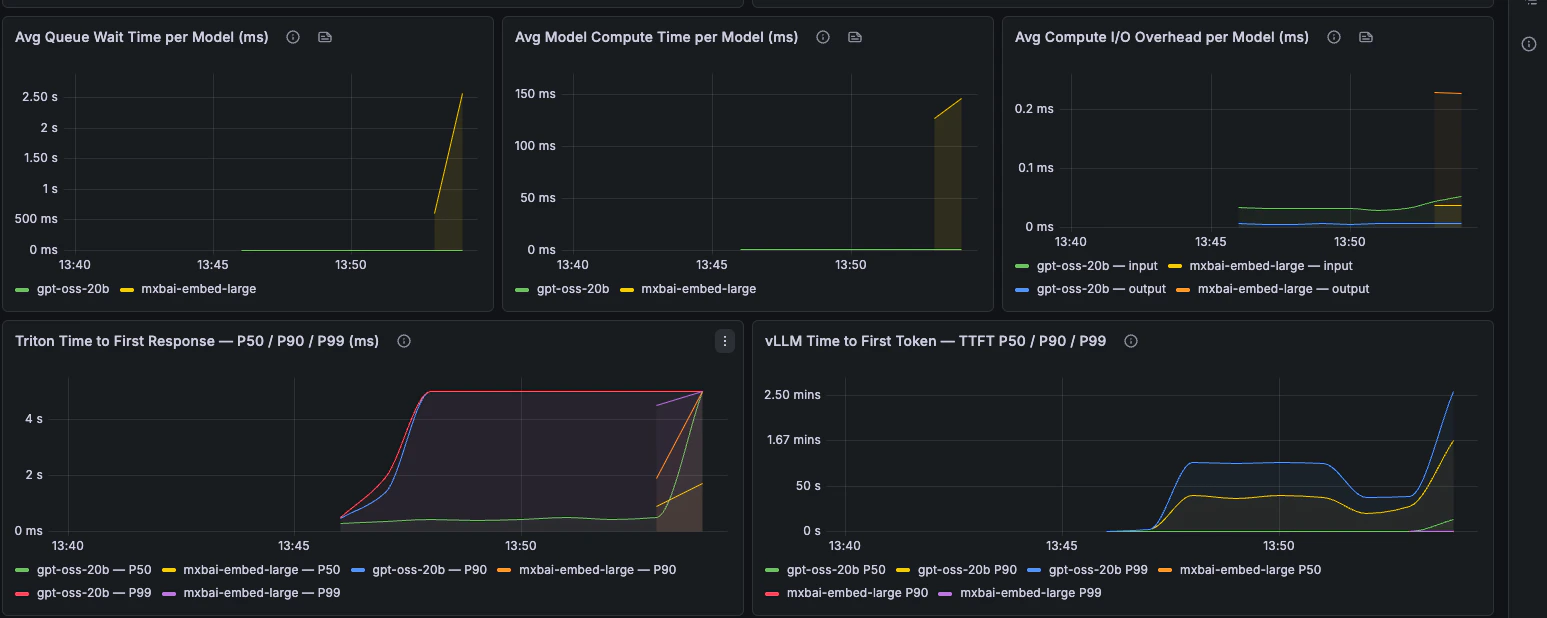
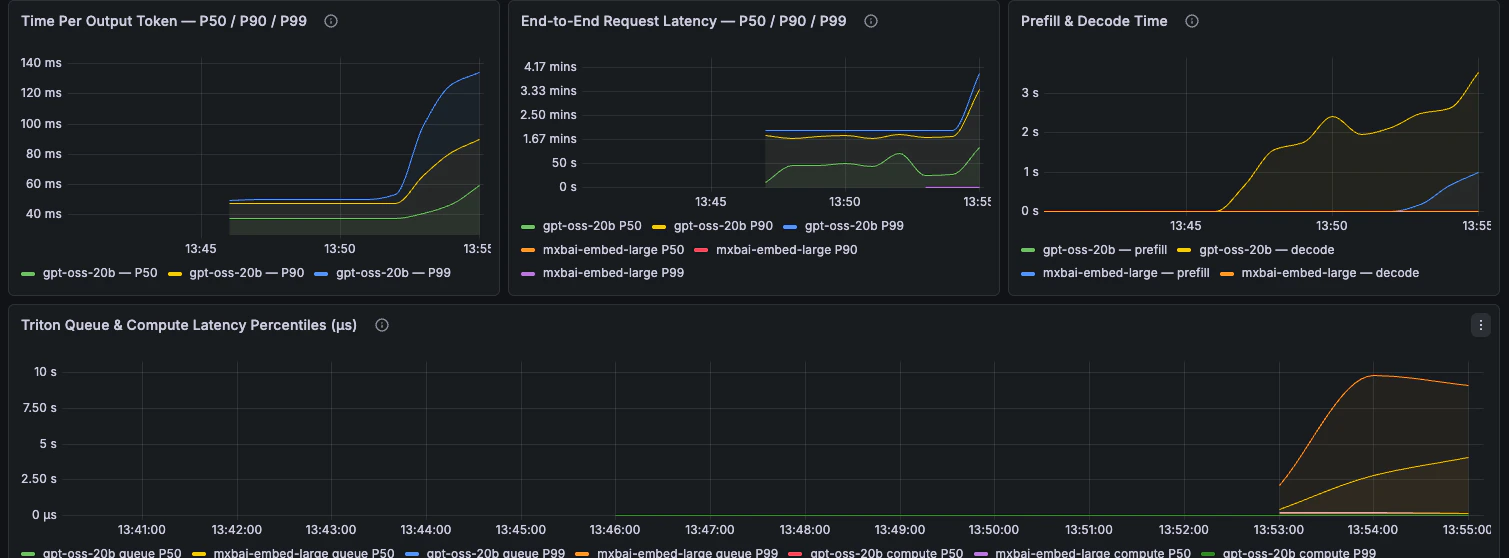
Latency
Latencia extremo a extremo, desglose por fases, TTFT, TPOT y percentiles de latencia de petición.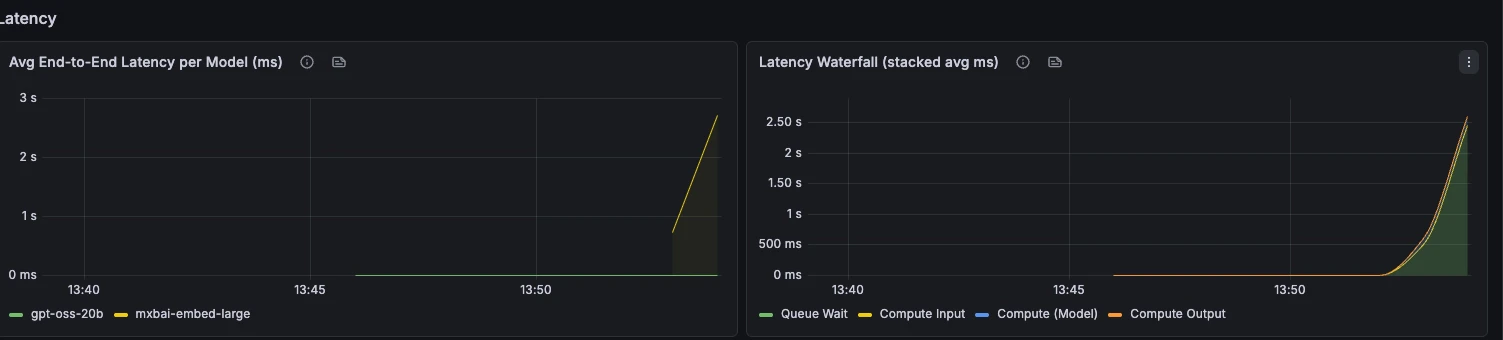
Capacity & Scheduler
Estado del scheduler, tiempo en cola, utilización de caché KV, preemptions y tamaño de batch.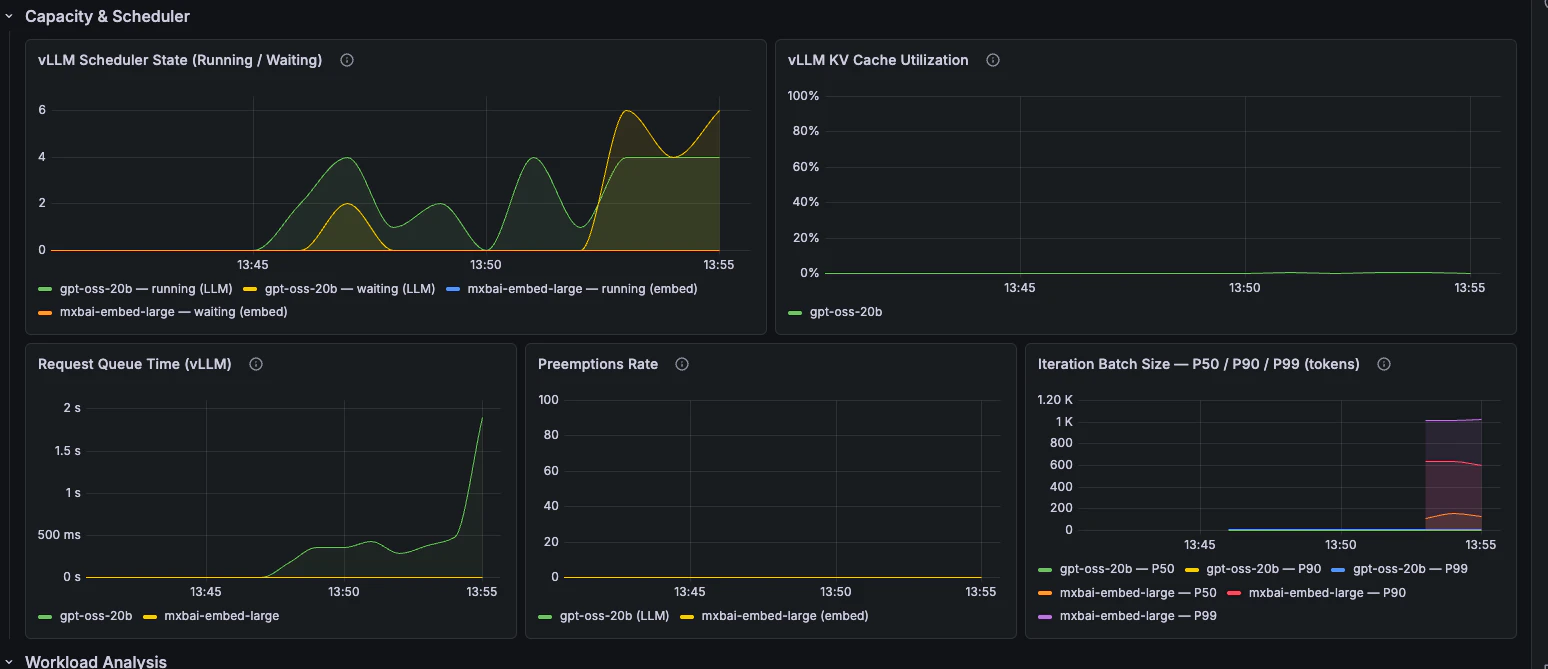
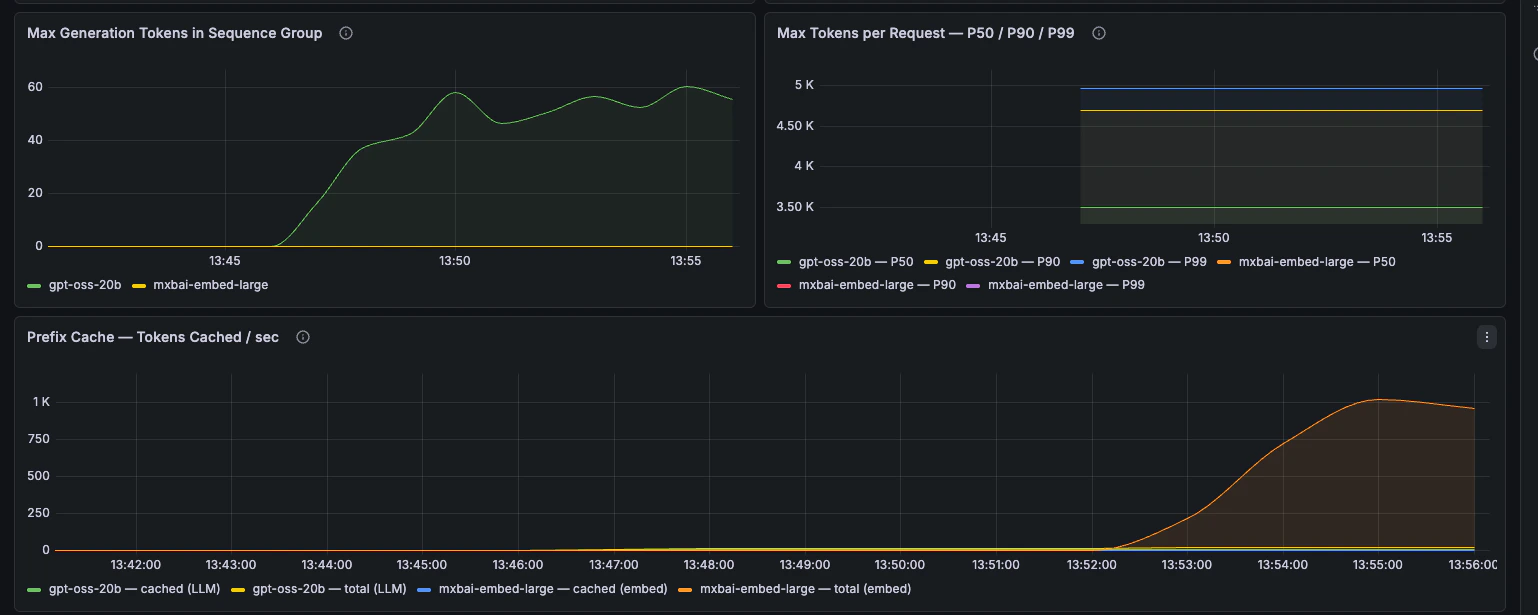
Workload Analysis
Rendimiento de tokens, longitud de prompts, longitud de generación y comportamiento de la caché de prefijos.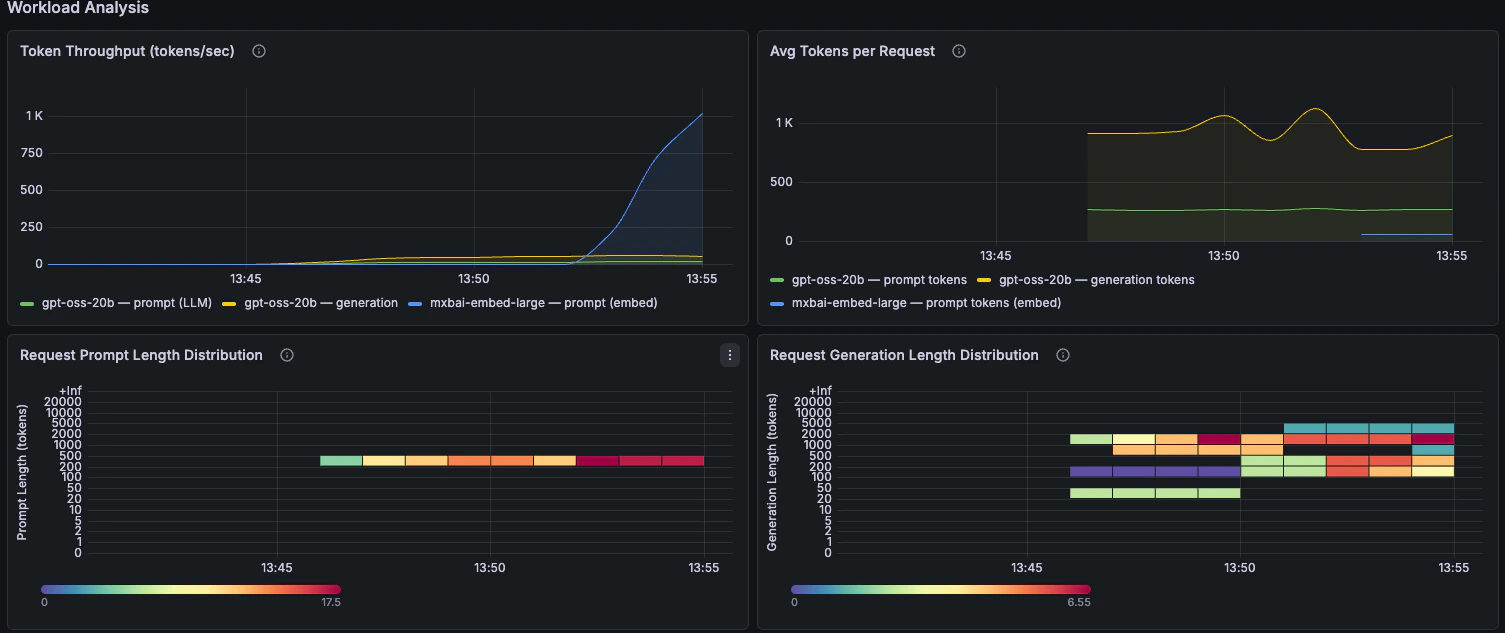
GPU Health
Utilización de GPU, presión de memoria, consumo energético y energía acumulada.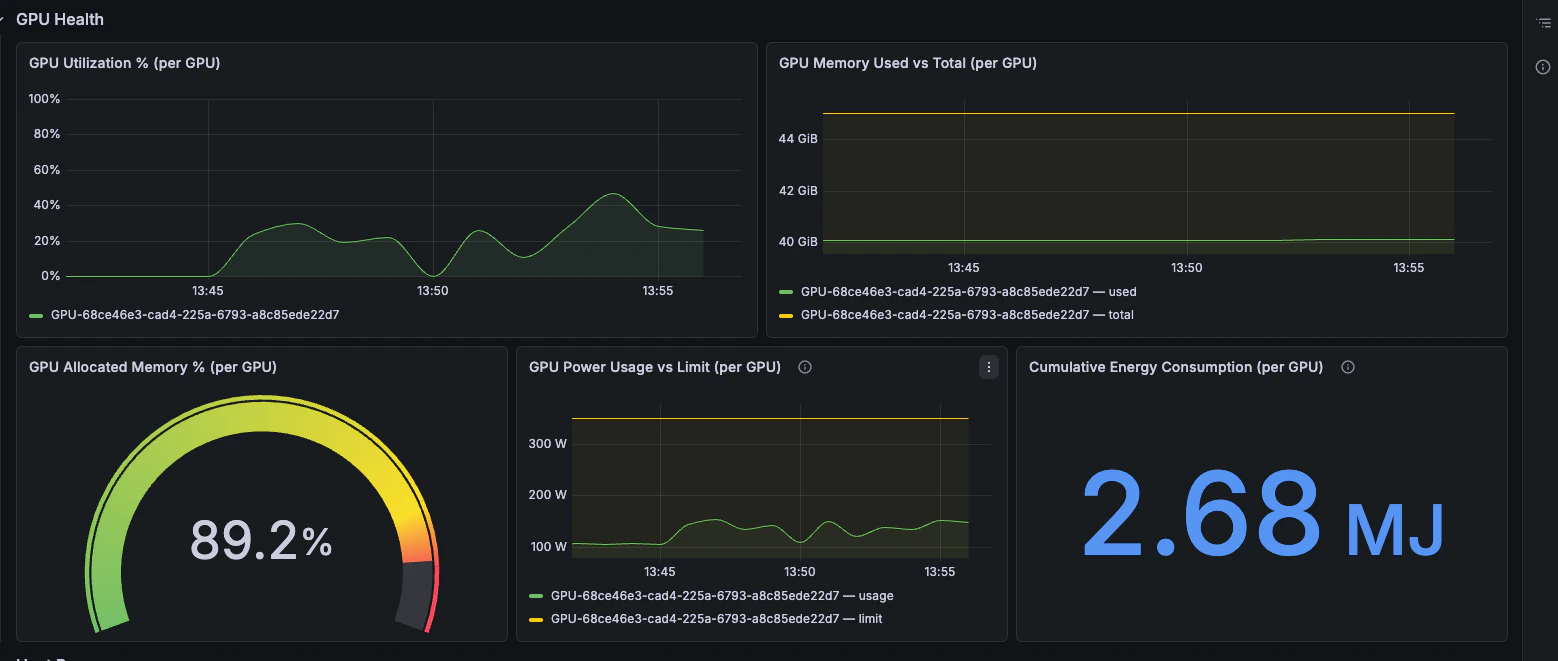
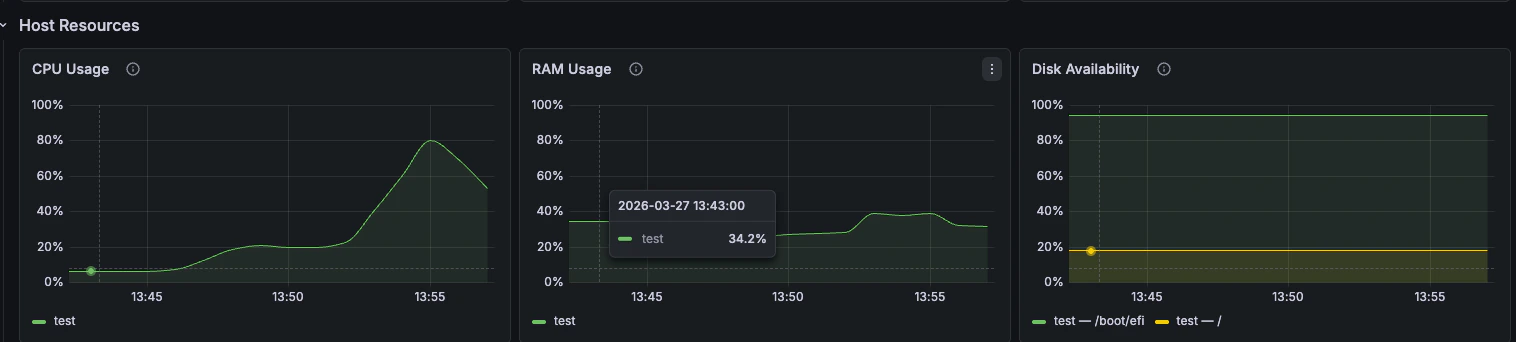
Host Resources
CPU, RAM y disponibilidad de disco desdenode_exporter.